软件的兼容
摘要
向上兼容等同于作向前兼容,向下兼容等同于向后兼容。主流使用的是向前兼容和向后兼容。向后兼容中“后”指“落后”,站在新版本的立场讨论过去版本的兼性问题。向前兼容中“前”指“前进”,表示未来的事情,站在旧版本的立场讨论未来版本的兼容性问题。
微软网站对“向后兼容”和“向前兼容”的理解:
向后兼容
2007 Microsoft Office 系统向后兼容下列早期版本:Microsoft Office 2000、Microsoft Office XP 和 Microsoft Office 2003。这些版本的用户可以轻松地采用新的格式,并继续从现有文件中获得最大的益处。特别是他们还可以继续使用旧的 .doc、.xls 和 .ppt 二进制格式,这些格式与 2007 文件格式完全兼容。
向前兼容
应用程序的早期版本能够打开较新版本中的文件并忽略早期版本中未实现的功能。例如,Word 2003 向前兼容 Word 2007,因为它能够成功地使用转换器打开 Word 2007 文件。
webpack异步加载组件原理.md
按需加载的好处
单页spa应用大行其道,但是我们往往开发过程中需要配置很多的路由引入。当打包构建的时候,javascript包会变得非常大,影响加载。如果我们能把不同路由对应的组件分割成不同的代码块,然后当路由被访问的时候才加载对应的组件,这样就更加高效了。这样会大大提高首屏显示的速度,但是可能其他的页面的速度就会降下来。结合Vue的异步组件和webpackde code splitting feature,轻松实现路由组件的懒加载。
就像图片的懒加载一样,如果客户根本就没有看到那些图片,而我们却在打开页面的时候全部给加载完了,这样会大大的增加请求的时间,降低用户的体验程度。懒加载在很多的网站都有用到,比如淘宝、京东等等这样的购物网站,上面的图片链接等等都很多,如果你把滚轴迅速的往下拉的时候,你可能会看到图片加载的情况。
单页应用也是一样,用户可能没有通过点击跳转到其他的的页面,而是只在主页面进行了停留,那么我们就没有必要把其他页面的资源全部加载过来。如果用户点进去再加载。这样就可以大大提高请求时间,提高用户的体验程度。
webpack中提供了require.ensure()来实现按需加载。以前引入路由是通过import 这样的方式引入,改为const定义的方式进行引入。
不进行页面按需加载引入方式:
1 | import home from '../../common/home.vue' |
进行页面按需加载的引入方式:
1 | const home = r => require.ensure( [], () => r (require('../../common/home.vue')) |
webpack ensure相信大家都听过。有人称它为异步加载,也有人说做代码切割,那这个家伙到底是用来干嘛的?其实说白了,它就是把js模块给独立导出一个.js文件的,然后使用这个模块的时候,webpack会构造script dom元素,由浏览器发起异步请求这个js文件。
需求场景分析:
比如应用的首页里面有个按钮,点击后可以打开某个地图。打开地图的话就要利用百度地图的js,于是我们不得不在首页中把百度地图的js一起打包进去首页,一个百度地图的js文件是非常大的,假设为1m,于是就造成了我们首页打包的js非常大,用户打开首页的时间就比较长了。有没有什么好的解决方法呢?
当然还是有的!我们细想,百度地图是用户点击了才弹出来的,也就是说,这个功能是可选的。那么解决方案就来了,能不能在用户点击的时候,我在去下载百度地图的js.当然可以。那如何实现用户点击的时候再去下载百度地图的js呢?于是,我们可以写一
个按钮的监听器
1 | mapBtn.click(function() { |
上面的几行代码对大家来说都不难。可以在点击的时候,才加载百度地图,等百度地图加载完成后,在利用百度地图的对象去执行我们的操作。ok,讲到这里webpack.ensure的原理也就讲了一大半了。它就是把一些js模块给独立出一个个js文件,然后需要用到的时候,在创建一个script对象,加入到document.head对象中即可,浏览器会自动帮我们发起请求,去请求这个js文件,在写个回调,去定义得到这个js文件后,需要做什么业务逻辑操作。
ok,那么我们就利用webpack的api去帮我们完成这样一件事情。点击后才进行异步加载百度地图js,上面的click加载js时我们自己写的,webpack可以轻松帮我们搞定这样的事情,而不用我们手写
1 | mapBtn.click(function() { |
搞定!当然还是分析一下。require.ensure这个函数是一个代码分离的分割线,表示 回调里面的require是我们想要进行分割出去的,即require(’./baidumap.js’),把baidumap.js分割出去,形成一个webpack打包的单独js文件。当然ensure里面也是可以写一些同步的require的,比如
1 | var sync = require('syncdemo.js') //下面ensure里面也用到 |
也就是说,ensure会把没有使用过的require资源进行独立分成成一个js文件. require.ensure的第一个参数是什么意思呢?[], 其实就是 当前这个 require.ensure所依赖的其他 异步加载的模块。你想啊?如果A 和 B都是异步加载的,B中需要A,那么B下载之前,是不是先要下载A啊?,所以ensure的第一个参数[]是它依赖的异步模块,但是这里需要注意的是,webpack会把参数里面的依赖异步模块和当前的需要分离出去的异步模块给一起打包成同一个js文件,这里可能会出现一个重复打包的问题, 假设A 和 B都是异步的, ensure A 中依赖B,ensure B中 依赖A,那么会生成两个文件,都包含A和B模块。 如果想加载A require.ensure([‘A.js’],function) 即可
说完了上面的原理。下面就实践一下
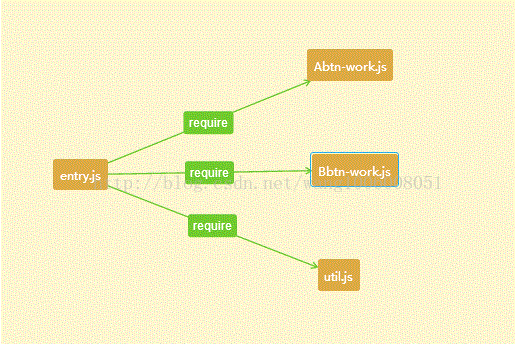
entry.js 依赖三个 js。
Abtn-work.js 是封装了 abtn按钮点击后,才执行的业务逻辑
Bbtn-work.js 是封装了 bbtn按钮点击后,才执行的业务逻辑
util.js 是封装了 entry.js需要利用的工具箱
针对上面的需求,优化方案
假设 Abtn-work.js Bbtn-work.js util.js都是非常大的文件因为 Abtn-work.js Bbtn-work.js 都不是entry.js必须有的,即可能发生的操作,那么我们把他们利用异步加载,当发生的时候再去加载就行了
util.js是entry.js立即马上依赖的工具箱。但是它又非常的大,所以将其配置打包成一个公共模块,利用浏览器的并发加载,加快下载速度。ok,构思完成,开始实现
index.html
1 | <!DOCTYPE html> |
可以看到,workA-async.js, workB-async.js 都是点击后才ensure进来的。什么时候加载完成呢?就是 require.ensure() 第二个函数参数,即回调函数,它表示当下载js完成后,发生的因为逻辑
webpack打包后,形成

其实, 1.1… 2.2…就是我们ensure导出来的js文件
我们看看代码是如何加载的执行的,点击打包插入js后的html
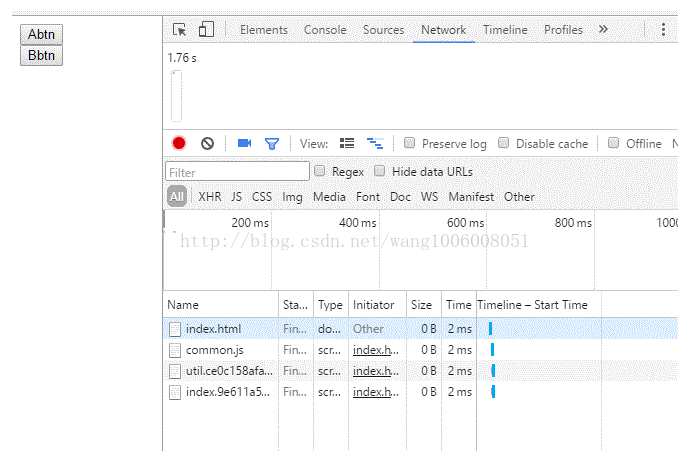
发现浏览器下载并加载了 1.1…js
点击 bbtn
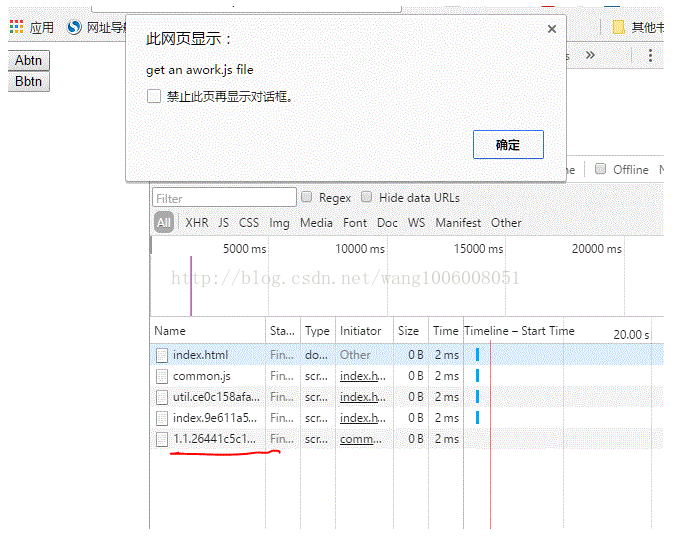
发现浏览器下载并加载了 2.2…js
其实项目优化,还有通过减少向服务器请求的次数来减少等待的时间。比如,一个页面的数据包括图片、文字等用户都已经加载完了,然后用户通过点击跳转到了另外一个界面。然后从另外一个界面通过返回又回到了原先的界面。如果没有设置的话,那么原先界面的信息就要重新向服务器请求得到。而通过vue提供的keep-alive可以是页面的已经请求的数据得以保存,减少请求的次数,提高用户的体验程度。
组件的按需加载
vue项目实现按需加载的3种方式:
- vue异步组件、
- es提案的import()
- webpack的require.ensure()
vue异步组件技术
在使用vue-router配置路由时,使用vue的异步组件技术,可以实现按需加载。
但是,这种情况下一个组件生成一个js文件。
举例如下:
1 | { |
es提案的import()
vue-router配置路由,代码如下:
1 | // 下面2行代码,没有指定webpackChunkName,每个组件打包成一个js文件。 |
webpack提供的require.ensure()
vue-router配置路由,使用webpack的require.ensure技术,也可以实现按需加载。
这种情况下,多个路由指定相同的chunkName,会合并打包成一个js文件。
举例如下:
1 | { |
prototype
函数的prototype属性
- 每个函数都会有一个prototype属性,它默认指向一个Object={}空对象(即原型对象)
- 原型对象中有一个constructor属性,指向函数对象
1 | function fun(){ |
输出如下:

给原型对象添加属性(多数是方法)
- 构造函数的所有实例对象会自动拥有原型中的属性(多数是方法)
1 | function Fun(){ |
js基础
前言
本文主要是基础知识的深化,内容包括:
数据类型:判断方法、变量类型与数据类型、数据在堆栈空间中的储存细节
对象:对象是多个(种)数据的容器,两种访问内部数据的方法
函数:函数也是对象,也有属性和方法。IIEF、this指向问题
数据类型
基本(值)类型
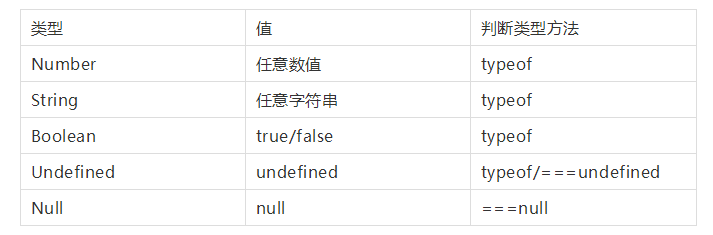
对象(引用)类型
数据、内存、变量
数据
存储在内存中的信息,以二进制(0101101)的形式保存,可传递
内存
内存条通电后产生的临时储存空间
- 一块“内存”(一个字节)包含两部分信息
- 内部储存的数据
- 该内存的地址值
- 内存空间分类
- 栈空间 全局变量/局部变量,表示对象名的变量,空间较小
- 堆空间 储存对象,空间较大
变量
变量名,用来查找到对应的内存
变量值,内存中保存的数据
总结
数据类型和变量类型不同,变量类型分为两种,一种保存值,一种保存地址
- 基本类型(保存值):保存基本类型的数据
- 引用类型(保存地址):保存对象类型的数据的地址
对象的理解与使用
什么是对象
保存多个数据(多种数据类型)的容器。这些数据每一个都有键名(key)和值(value)
对象的属性和方法
对象的属性和方法都是对象内部的数据,根据数据类型的不同划分为两类。
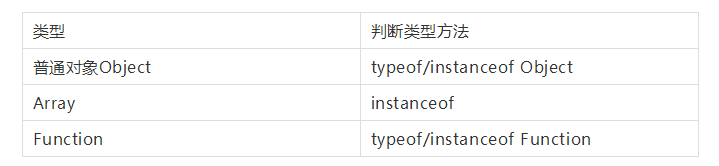
属性:保存的数据类型是基本类型、普通对象Object、数组类型Array
方法:保存的数据类型是函数类型Function
访问对象内部的数据
方法一(有时候不管用):.数据键名
方法二(通用方法):[‘数据键名’],数据键名有特殊字符/或者是一个变量
1 | var obj = {} |
函数的理解与使用
什么是函数
用来实现特定功能的, n条语句的封装体,可以执行
函数是对象,也有属性和方法
属性:test.prototype
方法:**test.call/apply(obj)**。这个方法可以让test临时成为obj的方法
IIEF
全名:Immediately-Invoked Function Expression立即调用函数表达,
别名:匿名函数自调用
作用:隐藏实现,不污染外部(全局)命名空间
1 | (function (i) { |
函数中的this
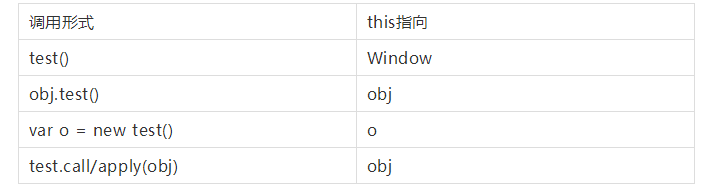
this是什么:
一个内置的引用变量,代表调用函数的当前对象,既然如此,那么this具体指的是谁,只有当函数执行才知道,谁调用,this就是谁。
如何确定this的值?这里假设已定义了函数test
package-lock.json需要写进.gitignore吗?
来源
npm 是有锁版本机制的,而package-lock.json文件是当 node_modules/ 或 package.json 发生变化时自动生成的文件,它的主要功能是 确定当前安装的包的依赖,以便后续重新安装的时候生成相同的依赖,而忽略项目开发过程中有些依赖已经发生的更新。
package-lock.json需要写进.gitignore吗?
package-lock.json 不应写进 .gitignore。这点无论你是否使用 lock 都是一样的。
具体来说:如果你使用 lock 机制,则应该将 package-lock.json 提交到 repo 中。比如 Vue 采取了该策略。如果你不使用 lock 机制,则应该加入 .npmrc 文件,内容为 package-lock=false ,并提交到 repo 中。比如 ESLint 采取了该策略。
例外是,如果你使用 yarn 并且不打算使用 npm,则可以把 package-lock.json 列入 .gitignore(比如 Babel);反之如果你使用 npm 并且不打算使用 yarn,则可以把 yarn.lock 列入 .gitignore (比如 TypeScript)。比如 jQuery 为什么把 package-lock.json 写入 .gitignore 。简单说就是 optional 依赖包会导致不同平台上的 package-lock.json 发生变更。jQuery 的人认为这有问题,所以暂时性 ignore 了它。先不管是不是有更好的方式或者其他 workaround,最新的 npm 5.6.0 其实已经解决了这个问题。
有一些不使用 lock 机制的库,已经使用了 .npmrc ,但也把 package-lock.json 列入了 .gitignore,这是没有必要的。
git基础
Git安装
安装完成后,用以下命令将用户信息全局初始化。
1 | $ git config --global user.name "Your Name" |
因为Git是分布式版本控制系统,所以,每个机器都必须自报家门:你的名字和Email地址。你也许会担心,如果有人故意冒充别人怎么办?这个不必担心,首先我们相信大家都是善良无知的群众,其次,真的有冒充的也是有办法可查的。
**注意: **git config命令的–global参数,用了这个参数,表示你这台机器上所有的Git仓库都会使用这个配置,当然也可以对某个仓库指定不同的用户名和Email地址。
创建版本库并初始化
1 | $ mkdir learngit |
以上三行命令分别为创建目录、进入目录以及查看当前目录位置。
注意: 路径中最好不要有中文
1 | $ git init |
初始化,会在此目录下建立一个隐藏的.git文件夹,用来跟踪管理版本库。
言归正传,现在我们编写一个readme.txt文件,内容如下:
1 | $ git add readme.txt |
添加文件,可连续多次添加。
1 | $ git commit -m "wrote a readme file" |
提交文件,把添加的所有文件一次提交,-m后面是提交信息,最好写有意义的描述。然后可以看到修改信息。
时光机穿梭
查看状态
先将原文件的第7行加入单词distributed ,然后在第8行后面添加一行Very Good!
显示当前库的状态,会提示变动过哪些文件。
1 | $ git status |
版本对比
查看和上一版本的具体变动内容
1 | $ git diff test.txt |
显示内容如下:
1 | diff --git a/test.txt b/test.txt |
详解:
- diff –git a/test.txt b/test.txt ——对比两个文件,其中a改动前,b是改动后,以git的diff格式显示;
- index 629d9c8..3d98a7f 100644 ——两个版本的git哈希值,index区域(add之后)的 629d9c8 对象和工作区域的 3d98a7f 对象, 100表示普通文件,644表示权限控制;
- — a/test.txt +++ b/test.txt ——减号表示变动前,加号表示变动后;
- @@ -4,8 +4,9 @@ test line3. ——@@表示文件变动描述合并显示的开始和结束,一般在变动前后多显示3行,其中-+表示变动前后,逗号前是起始行位置,逗号后为从起始行往后几行。合起来变动前后都是从第4行开始,变动前文件往后数8行对应变动后文件往后数9行。
- 变动内容 ——+表示增加了这一行,-表示删除了这一行,没符号表示此行没有变动。
版本回退
1 | $ git log |
用来查看最近三次提交的记录
1 | $ git log --pretty=oneline |
合并每条记录到一行
1 | $ git reset --hard HEAD^ |
向前回退版本,其中HEAD后面跟几个^就是往回退几个版本,如果回退100个版本,可以写成 HEAD~100 。
1 | $ git reset --hard 07e0 |
向后恢复版本,首先要查找到对应版本的哈希id前4位,如果提交窗口找不到,可以使用以下命令
1 | $ git reflog |
这个命令记录了每一次版本相关的操作。git回退的速度非常快,因为在git内部有一个指向当前版本的HEAD指针,回退到某个版本,实际上是git把指针移动指向某个版本
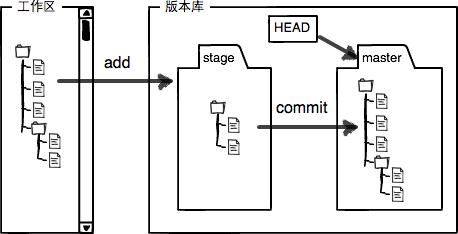
工作区和暂存区
- 工作区(Working Directory):.git所在的目录下,除了.git之外的其他文件都是在工作区内
- 版本库(Repository):.git目录内所存的记录,有暂存区和Git为我们自动创建的第一个分支master,以及指向master的一个指针叫HEAD。
- stage(或者叫index)的暂存区:用add命令放进来文件的位置
- 如果文件在工作区被编辑,对应的status状态就是 Changes not staged for commit
- 如果工作区新增文件,则对应的status状态就是 Untracked files
- 如果文件被add后,对应的status状态就是 Changes to be committed
- 多次add后的文件都放在暂存区,最后一次性全部提交。提交后的status状态就是 nothing to commit, working tree clean这时候工作区就是干净的,暂存区就没有任何内容了。
修改
管理修改
如果一个文件,修改一次后,add,再修改一次后直接commit,然后status则显示还有一次修改没有被提交,因为提交只对暂存区生效。所以要么每改动一次后都add,最后一次性提交;要么add一次就提交一次。
比较工作区与暂存区
git diff 不加参数即默认比较工作区与暂存区
比较暂存区与最新本地版本库(本地库中最近一次commit的内容)
git diff –cached [
比较工作区与最新本地版本库
git diff HEAD [
撤销修改
如果在工作区修改了文件后的status,会提示,下一步可以add到暂存区,或者从暂存区恢复修改:
1 | Changes not staged for commit: |
想要撤销,就用第3行的命令
$ git checkout – test.txt
如果已经add到暂存区了,这时想要撤销操作,这时可以从status中的提示——从HEAD中恢复修改。
$ git reset HEAD
但这时候暂存区的修改撤销了,工作区还是修改后的内容,此时再使用上面提交的 $ git checkout – test.txt 来撤销工作区修改,世界终于变得清净了!
删除文件
1 | $ rm test2.txt |
此命令可以从工作区删掉文件。如果要从版本库中删除,则add后提交即可,如果是误删了,则通过
1 | $ git checkout -- test2.txt |
从版本库里恢复。
如果已经将删除提交,则像前面一样先恢复版本库,然后在checkout出要恢复的文件。
分支管理
##概述
假设你准备开发一个新功能,但是需要两周才能完成,第一周你写了50%的代码,如果立刻提交,由于代码还没写完,不完整的代码库会导致别人不能干活了。如果等代码全部写完再一次提交,又存在丢失每天进度的巨大风险。这种情况下需要分支来管理。自己在创建的新分支上进行开发,完成后一次性提交合并即可。
Git对于分支的创建、切换和删除都能非常快的实现,而SVN就很慢。
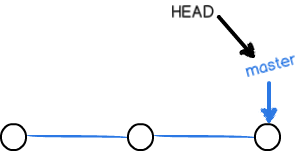
创建与合并分支
git单分支的结构是这样的,master是指向最新提交的指针,HEAD是指向master的指针,每做一次提交,指针就向前移动一步:
现在增加一个dev分支并切换到这个分支:
1 | $ git -b checkout dev |
这个代码可以写成两步,本别是创建新分支 $ git branch dev ,切换到目标分支 $ git checkout dev ,之后变成这样: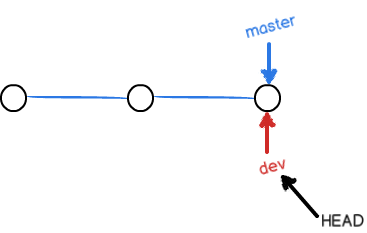
这时可以用命令查看分支
1 | $ git branch |
其中带星号的是当前所在分支。然后再新分支上做一些更改,再add并提交,这是结构变成了这样: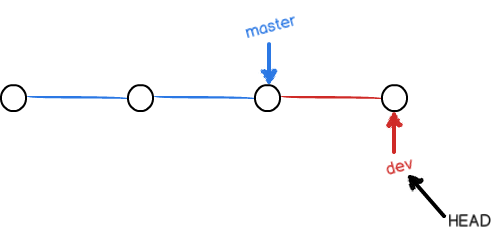
切换回master($ git checkout master )分支后,发现刚才所做的改动不见了,是因为改动在dev分支上。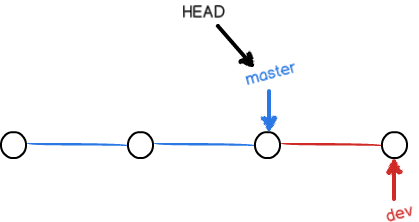
这时使用合并命令:
1 | $ git merge dev |
即把目标分支合并到当前分支上。完成后提示 Fast-forward ,说明系统用了快进模式进行合并,此时的结构为:
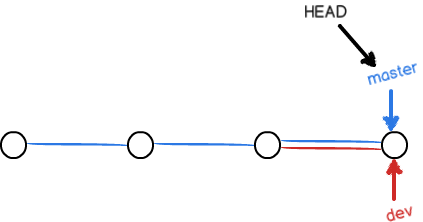
master分支上也成了最新版。这时不需要dev分支了,可以删除:
1 | $ git branch -d dev |
这时再查看分支,已经没有dev了。
解决冲突
当两个分支上对同一个文件有修改并分别有提交,最后Git无法自动合并,就会产生冲突。
1 | $ git merge 'feature2' |
如果你不服气再执行一次合并,就会看到:
1 | $ git merge feature2 |
这时候可以通过 git status 查看冲突信息,找到描述中冲突的文件:
1 | <<<<<<< HEAD |
其中 <<<<<<< HEAD 和 ======= 之间是当前分支的最新版, ======= 和 >>>>>>> f4 之间是目标分支内容,手动修改后删掉这些符号,然后提交,结构如图:
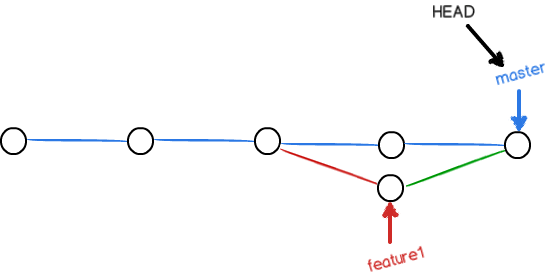
可以用以下代码看到图形化流程:
$ git log –graph –pretty=oneline –abbrev-commit
其中, –graph 是图形化, –pretty=oneline 是一行显示, –abbrev-commit 是只显示每次提交id的前几位,显示效果如下:
分支管理策略
默认情况下,如果情况允许,Git会自动用快进模式合并分支,但这样合并后不会留下分支存在过的痕迹。删除分支后就会丢失相应信息。如果不想这样做,则在合并时加上参数 –no-ff ,Git则会生成一个提交,所以同时再加上一个提交信息(如果不加则会进入vim模式让编辑提交信息),代码如下:
$ git merge –no-ff -m “merge with no-ff” dev
这样合并后还能看到对应的分支信息,如图,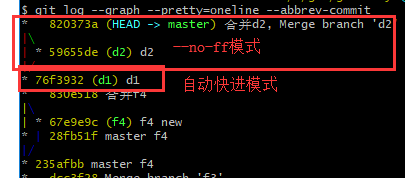
实际开发中的分支策略:
首先,master分支应该是非常稳定的,也就是仅用来发布新版本,平时不能在上面干活;
平时大家在dev分支上干活,需要发布时合并到master分支即可。
Bug分支
假设正在dev上开发,突然接到修复master上一个bug,就可以用如下命令把现场保存起来(这个命令比其他命令要执行的慢):
$ git stash
这时工作区就是干净的,刚才的改动不见了。然后把分支切换到master,并在此基础上新建并切换到bug分支issue-101,在这里修复bug。修复完成后回到master分支,进行非快速合并后删除bug分支,再切换回dev分支,可以通过加list参数看到 stash 的列表:
$ git stash list
stash@{0}: WIP on d3: 820373a 合并d2, Merge branch ‘d2’
通过如下命令恢复现场:
$ git stash apply
这时stash区的内容还存在,可以用list查看,如果要清理掉,就用
$ git stash drop
这时stash区什么都没了。如果将工作区内容多次保存到stash,则可以加 stash@{0} 这样的编号来指定恢复哪个(可用list参数查看编号)。
$ git stash apply stash@{0}
也可以用如下命令弹出最后一次保存的工作区内容,这个命令会将对应的stash内容清除掉。
$ git stash pop
Feature分支——强行删除分支
如果在master分支上删除一个已经提交但没有合并的其它分支,则会报错:
$ git branch -d f5
error: The branch ‘f5’ is not fully merged.
If you are sure you want to delete it, run ‘git branch -D f5’.
这时可以用参数 -D 强制删除:
$ git branch -D f5
需要注意的是,由于分支未合并,删除之后就没有任何记录了,分支上所有的修改也会丢失。
多人协作
先来两个命令:
$ git remote
查看远程仓库名称
$ git remote -v
查看远程仓库更详细的信息
场景:我本地有master和dev两个分支,但我只把master推送到远程仓库中。然后我的小伙伴从远程的master分支上克隆了一份,他是看不到我本地dev分支的。然后自己在本地新建dev分支进行开发,完了之后推送到远程仓库。同时我在本地 的dev分支修改了跟他一样的文件。这时我准备推送代码,就会报错,提示先pull同步代码, 但拉取的时候又报错,说没有指定本地dev和远程origin/dev之间的连接( There is no tracking information for the current branch. )。可通过以下代码进行关联:
$ git branch –set-upstream-to=origin/dev dev
然后再pull,解决冲突,再提交,再push,跟前面一样。
补充 :从远程git仓库里的指定分支拉取到本地(本地不存在的分支)
git checkout -b 本地分支名 origin/远程分支名
然后再 pull
Rebase
Rebase用来整理提交记录,把多条分叉合并成一条直线。
假设有代码:
1 | $ git log --graph --pretty=oneline --abbrev-commit |
Git用(HEAD -> master)和(origin/master)标识出当前分支的HEAD和远程origin的位置分别是582d922 add author和d1be385 init hello,本地分支比远程分支快两个提交。假设推送时发现有人改了同样文件导致冲突,pull下来解决后再提交,这时本地分支会比远程超前3个提交。
1 | $ git log --graph --pretty=oneline --abbrev-commit |
如果觉得这种分叉的图形看起来乱,可以用如下命令整理一下:
$ git rebase
整理后查看到的记录为:
1 | $ git log --graph --pretty=oneline --abbrev-commit |
发现Git把我们本地的提交“挪动”了位置,放到了f005ed4 (origin/master) set exit=1之后,这样,整个提交历史就成了一条直线。修改不再基于d1be385 init hello,而是基于f005ed4 (origin/master) set exit=1,但最后的提交7e61ed4内容是一致的。推送之后如图:
1 | $ git log --graph --pretty=oneline --abbrev-commit |
远程和本地都成了一条直线。
Rebase的缺点是会更改我们的本地提交,但合并后的内容是一致的。
标签管理
Git的标签就是版本库的快照,但其实它就是指向某个commit的指针。
创建标签
1 | $ git tag v1.0 |
给当前的commit打上标签 v1.0
1 | $ git tag |
查看所有标签,经测试在dev分支上能看到master上所有标签,尽管dev上面的commit要少很多。
注意,标签不是按时间顺序列出,而是按字母排序的
1 | $ git tag v0.9 f52c633 |
可以给历史commit打上标签,最后一个参数是commit的前几位(通过git log查看)
1 | $ git tag -a v0.1 -m "version 0.1 released" 1094adb |
创建带有注释的标签,-a后面是标签名,-m后面是注释内容
1 | $ git show v0.1 |
查看标签名为 v0.1的详细内容
操作标签
1 | $ git tag -d v0.1 |
删除本地标签
1 | $ git push origin v1.0 |
将标签 v1.0 推送到远程仓库
1 | $ git push origin --tags |
将尚未推送的标签全部推送到远程仓库
如果要删除远程仓库的标签,有以下两个步骤:
- 删除本地标签,见上
- 删除远程仓库对应标签 $ git push origin :refs/tags/v0.9