关于ECMAScript2017特性SharedArrayBuffer和atomics的背景知识:
- 内存管理的速成课程
- ArrayBuffers和SharedArrayBuffers的介绍
- [使用Atomics避免SharedArrayBuffers中的竞争条件]
使用Atomics避免SharedArrayBuffers中的竞争条件
在上一部分中,我谈到了使用SharedArrayBuffers如何导致竞争条件。这使得使用SharedArrayBuffers变得困难。我们不希望应用程序开发人员直接使用SharedArrayBuffers。
但是,具有其他语言多线程编程经验的库开发人员可以使用这些新的低级API来创建更高级别的工具。然后,应用程序开发人员可以直接使用这些工具而无需触及SharedArrayBuffers或Atomics。
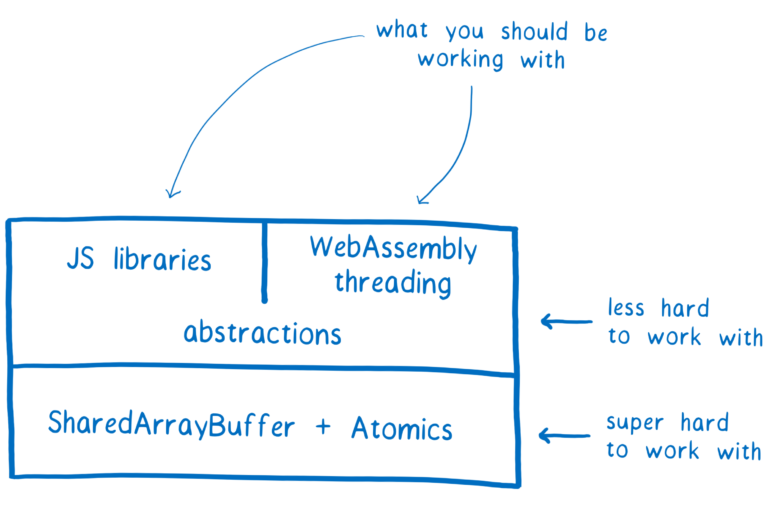
即使您可能不应该直接使用SharedArrayBuffers和Atomics,我认为了解它们的工作原理仍然很有趣。因此,在本文中,我将解释并发可以带来什么样的竞争条件,以及Atomics如何帮助库避免它们。
但首先,什么是竞争条件?
比赛条件:您可能已经看过的一个例子
当你有一个在两个线程之间共享的变量时,就会发生一个非常简单的竞争条件示例。假设一个线程想要加载一个文件而另一个线程检查它是否存在。他们共享一个变量fileExists,进行沟通。
最初,fileExists设置为false。

只要线程2中的代码首先运行,就会加载该文件。
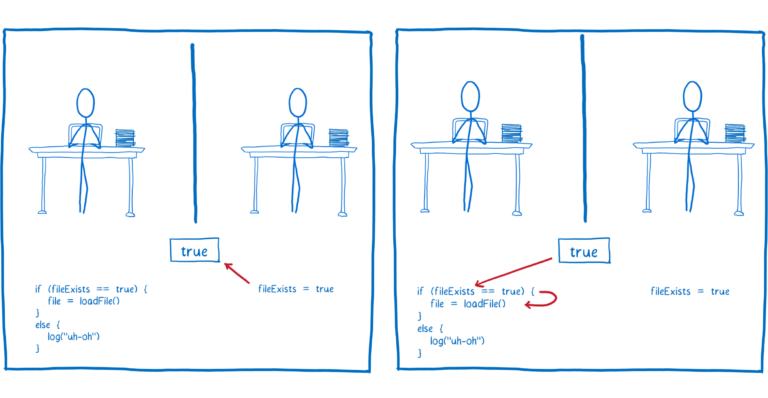
但是如果线程1中的代码首先运行,那么它将向用户记录一个错误,说该文件不存在。
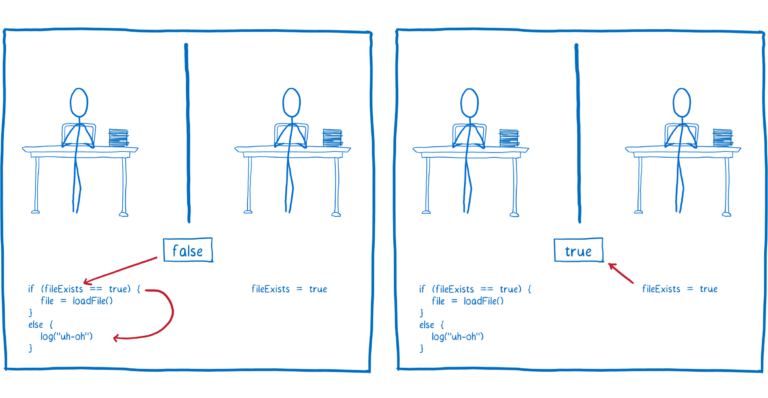
但那不是问题。这不是文件不存在。真正的问题是竞争条件。
许多JavaScript开发人员都遇到过这种竞争条件,即使在单线程代码中也是如此。你不必了解多线程的任何信息,看看为什么这是一场比赛。
但是,有些种类的竞争条件在单线程代码中是不可能的,但是当您使用多个线程编程并且这些线程共享内存时可能会发生这种情况。
不同类别的竞争条件以及Atomics如何提供帮助
让我们探讨一下您可以在多线程代码中使用的各种竞争条件以及Atomics如何帮助防止它们。这并未涵盖所有可能的竞争条件,但应该让您知道为什么API提供它所执行的方法。
在我们开始之前,我想再说一遍:你不应该直接使用Atomics。编写多线程代码是一个众所周知的难题。相反,您应该使用可靠的库来处理多线程代码中的共享内存。

随着那个…
单次操作中的比赛条件
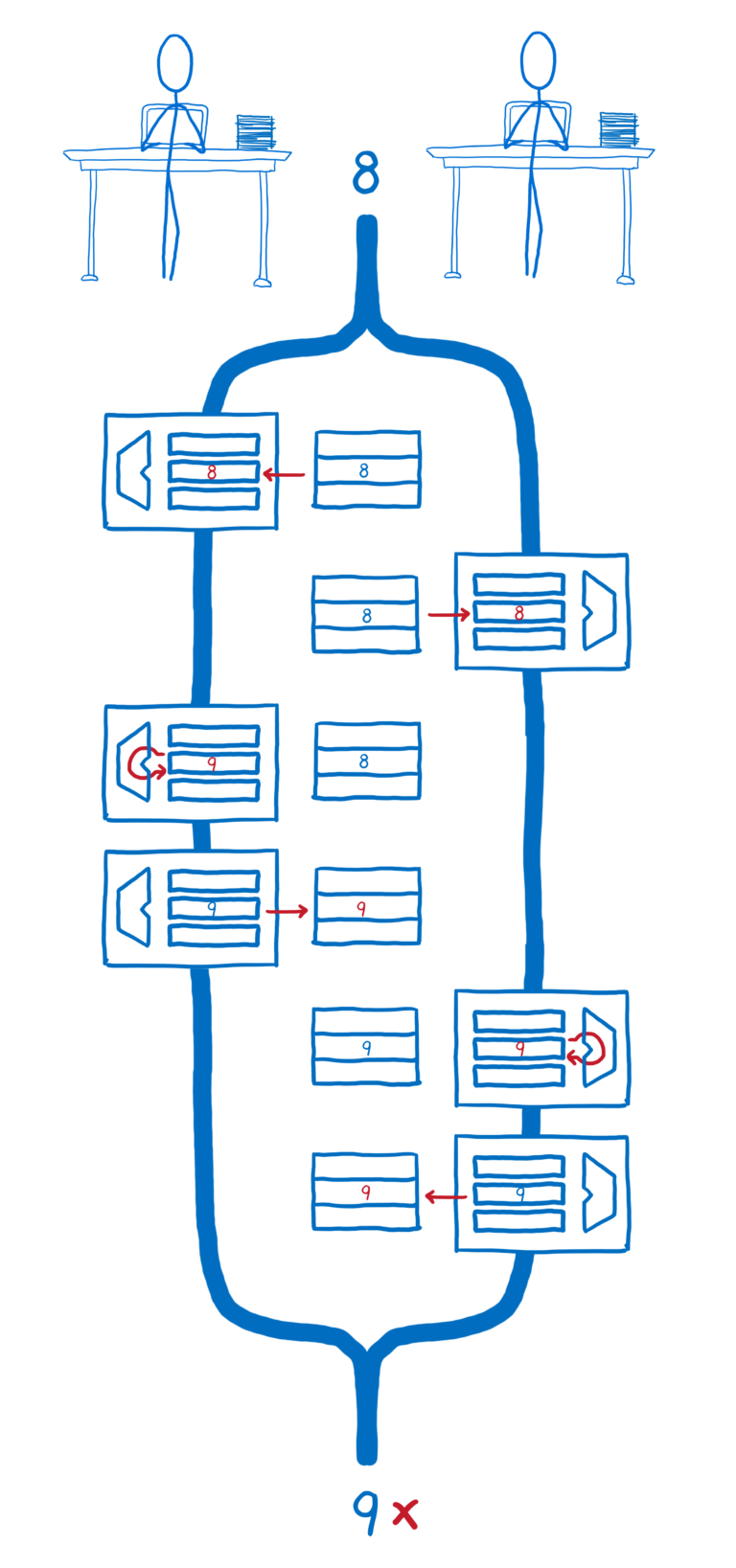
假设您有两个线程正在递增相同的变量。您可能认为无论哪个线程首先出现,最终结果都是相同的。
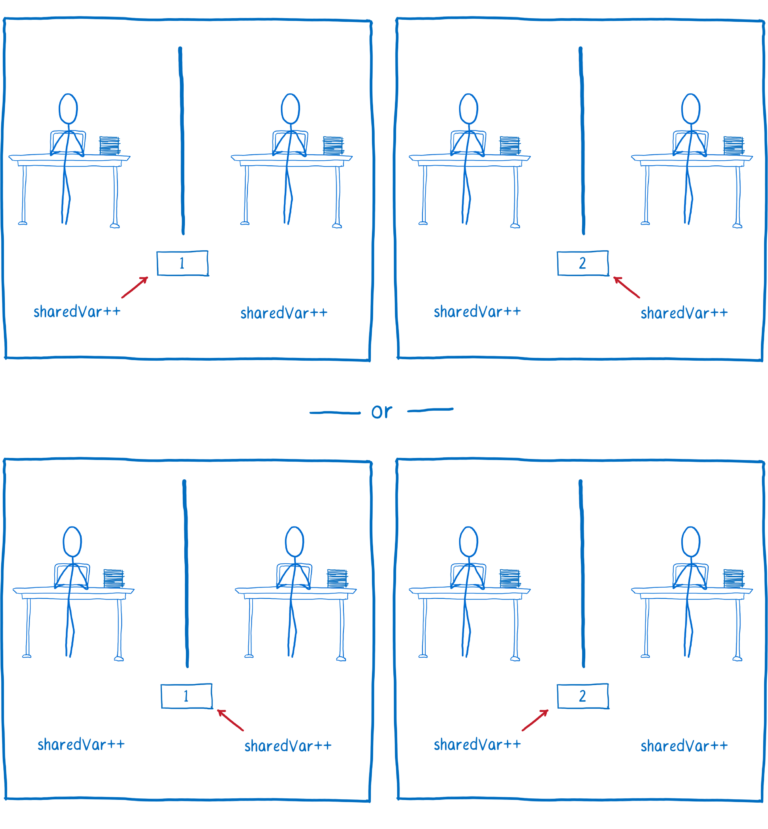
但即使在源代码中,递增变量看起来像一个操作,当您查看已编译的代码时,它不是单个操作。
在CPU级别,递增值需要三条指令。这是因为计算机具有长期记忆和短期记忆。(我在另一部分中更多地讨论了这一切是如何工作的)。
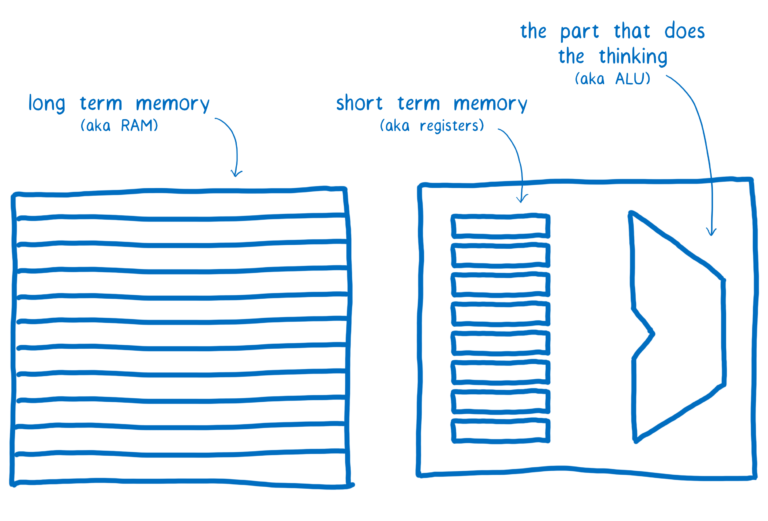
所有线程共享长期记忆。但短期内存 - 寄存器 - 不在线程之间共享。
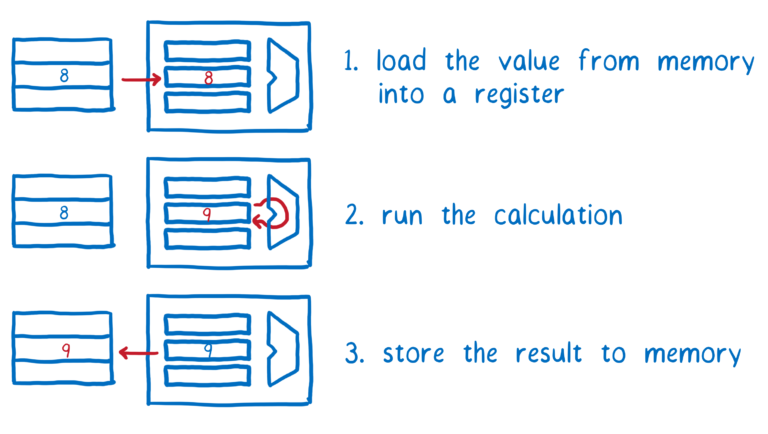
每个线程都需要将内存中的值拉入其短期内存中。之后,它可以在短期记忆中对该值进行计算。然后它将该值从其短期记忆中写回到长期记忆中。
如果线程1中的所有操作首先发生,然后线程2中的所有操作都发生,我们将得到我们想要的结果。
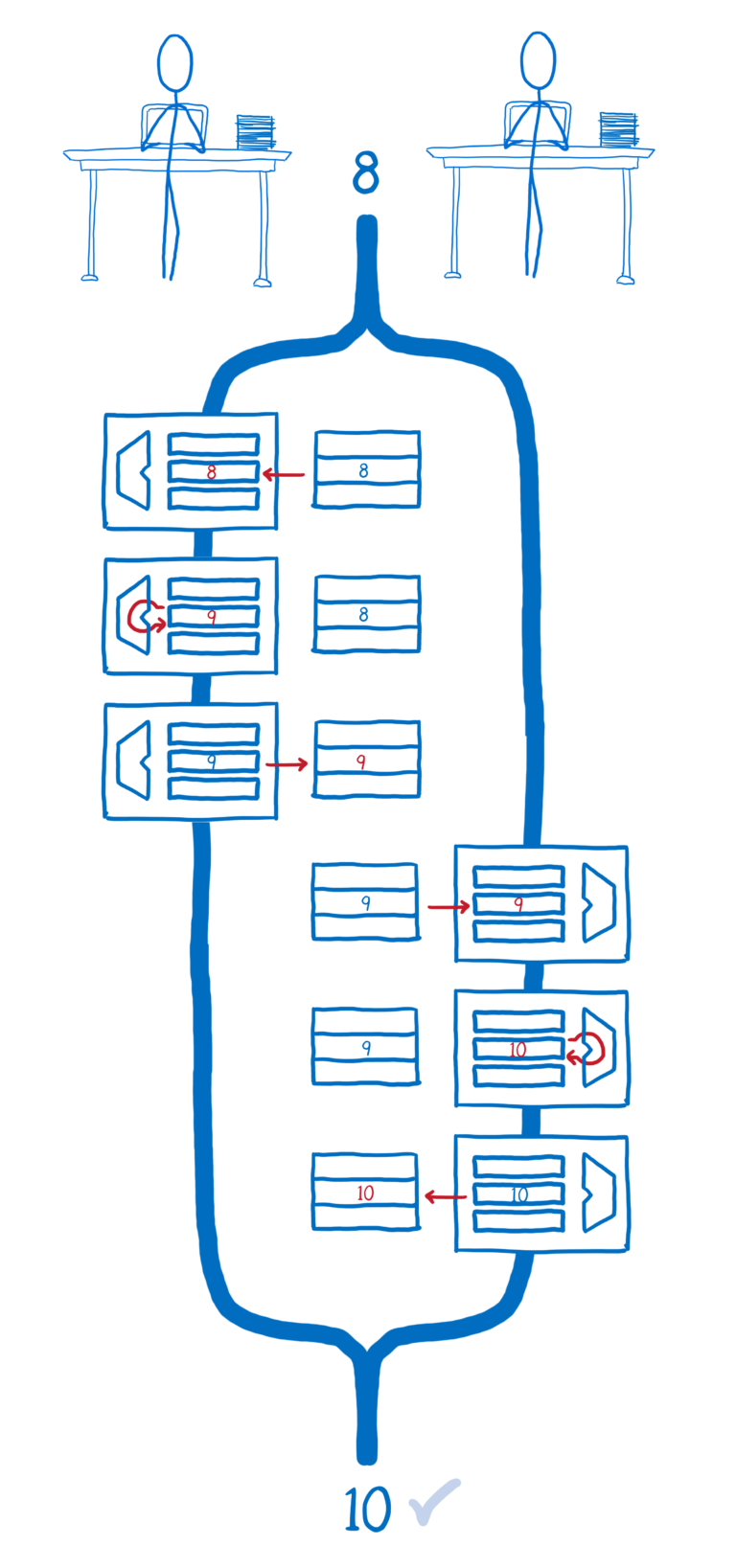
但是如果它们在时间上交错,则线程2拉入其寄存器的值与内存中的值不同步。这意味着线程2不考虑线程1的计算。相反,它只是破坏了线程1用自己的值写入内存的值。
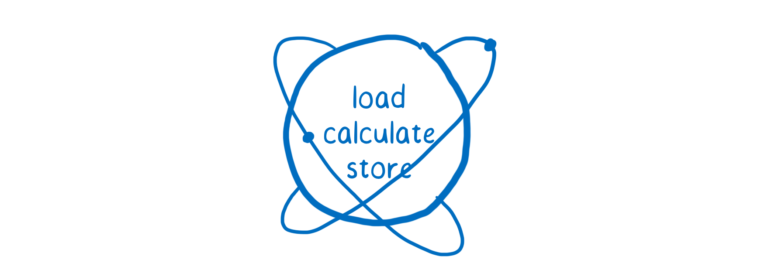
原子操作所做的一件事是将人类认为是单个操作的这些操作,但计算机视为多个操作,并使计算机将它们视为单个操作。
这就是他们被称为原子操作的原因。这是因为他们采取的操作通常会有多个指令 - 指令可以暂停和恢复 - 并且它使得它们看起来都是瞬间发生的,就像它是一条指令一样。它就像一个不可分割的原子。
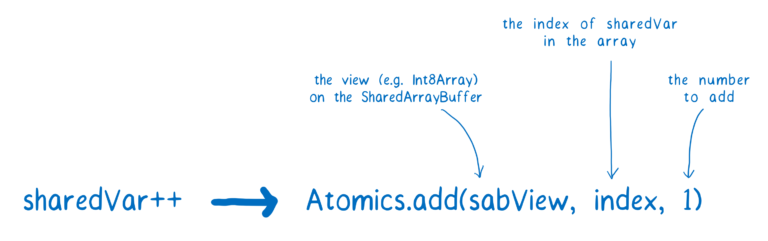
使用原子操作,递增的代码看起来会有所不同。
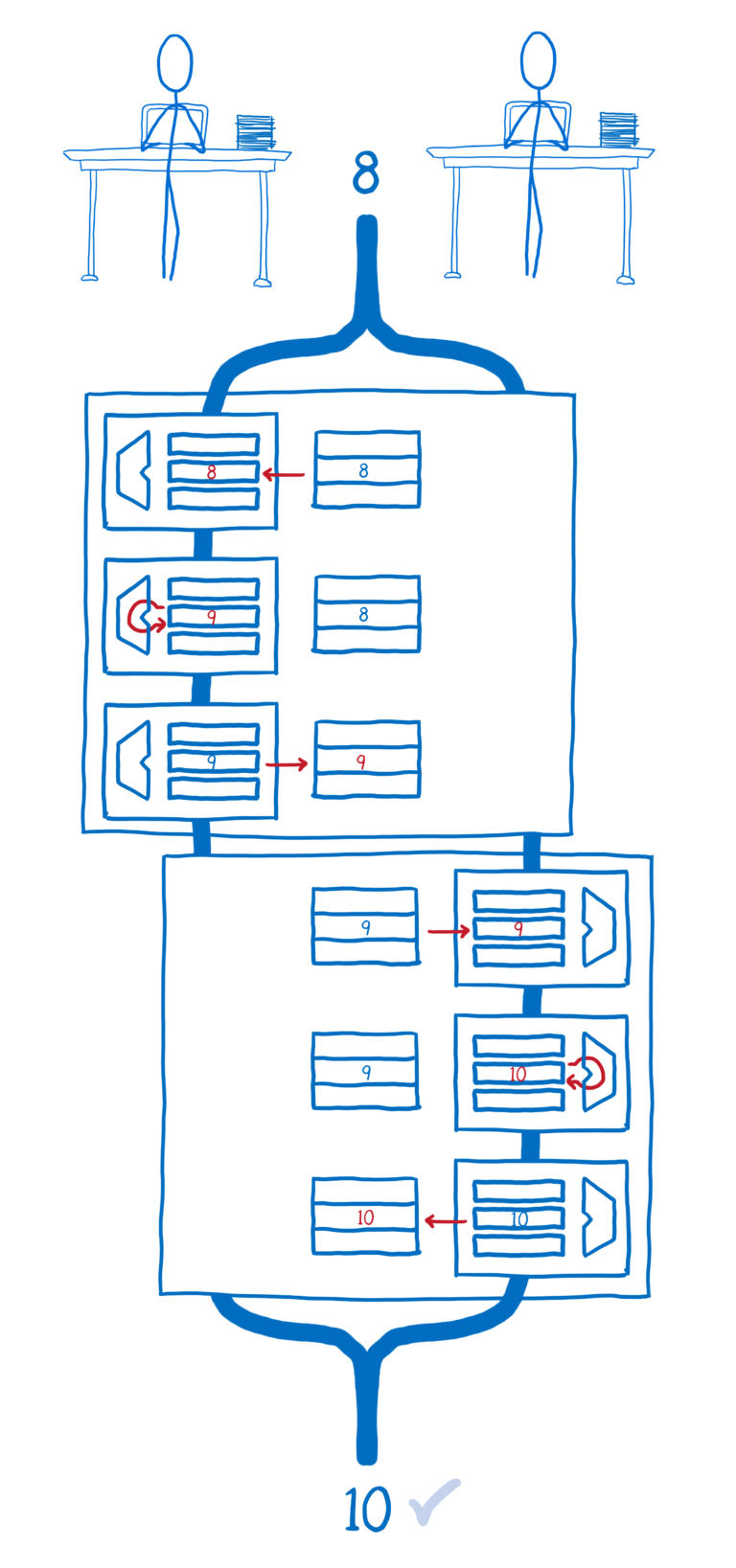
现在我们正在使用Atomics.add,增加变量所涉及的不同步骤不会在线程之间混淆。相反,一个线程将完成其原子操作并阻止另一个线程启动。然后另一个将开始自己的原子操作。
有助于避免这种竞争的原子方法是:
- Atomics.add
- Atomics.sub
- Atomics.and
- Atomics.or
- Atomics.xor
- Atomics.exchange
您会注意到此列表相当有限。它甚至不包括除法和乘法之类的东西。但是,库开发人员可以为其他事情创建类似原子的操作。
为此,开发人员将使用Atomics.compareExchange。这样,您可以从SharedArrayBuffer获取一个值,对其执行操作,并且如果您第一次检查后没有其他线程更新它,则只将其写回SharedArrayBuffer。如果另一个线程已更新它,那么您可以获取该新值并再试一次。
多个操作的竞争条件
因此,这些原子操作有助于在“单一操作”期间避免竞争条件。但有时您希望更改对象上的多个值(使用多个操作)并确保没有其他人同时对该对象进行更改。基本上,这意味着在对象的每次更改过程中,该对象都处于锁定状态,并且其他线程无法访问。
Atomics对象不提供任何直接处理此工具的工具。但它确实提供了图书馆作者可以用来处理这个问题的工具。库作者可以创建的是锁。
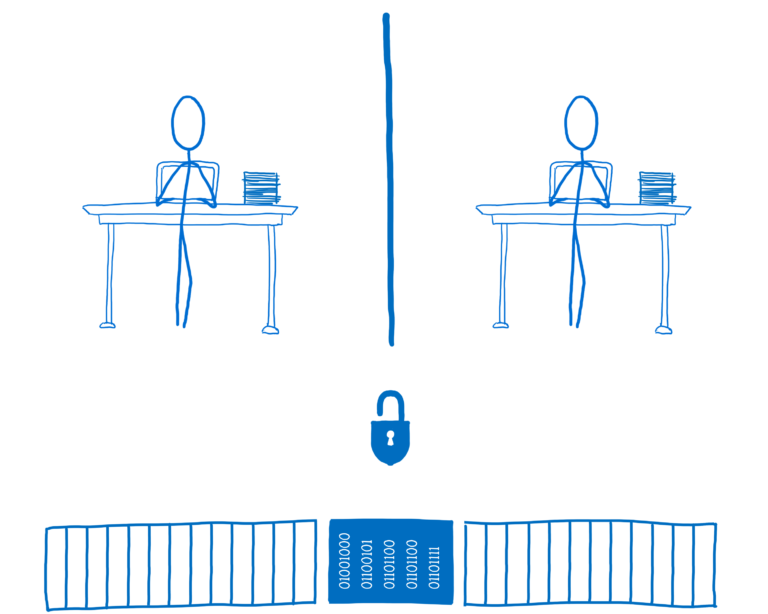
如果代码想要使用锁定数据,则必须获取数据锁。然后它可以使用锁来锁定其他线程。只有在锁定处于活动状态时才能访问或更新数据。
要构建锁,库作者将使用Atomics.wait和Atomics.wake,以及其他诸如Atomics.compareExchange和Atomics.store。如果您想了解这些是如何工作的,请看一下这个基本的锁实现。
在这种情况下,线程2将获取数据的锁定并将值设置locked为true。这意味着在线程2解锁之前,线程1无法访问数据。
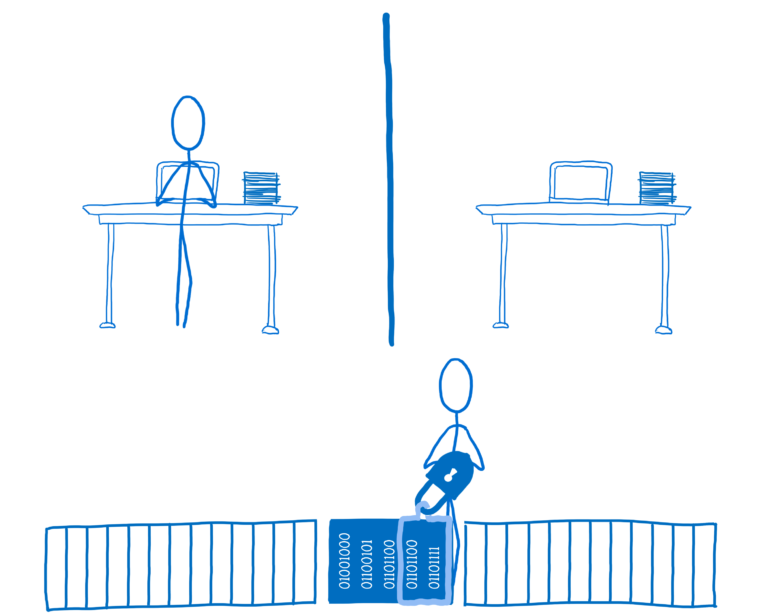
如果线程1需要访问数据,它将尝试获取锁。但由于锁已经在使用,它不能。然后线程将等待 - 因此它将被阻止 - 直到锁可用。
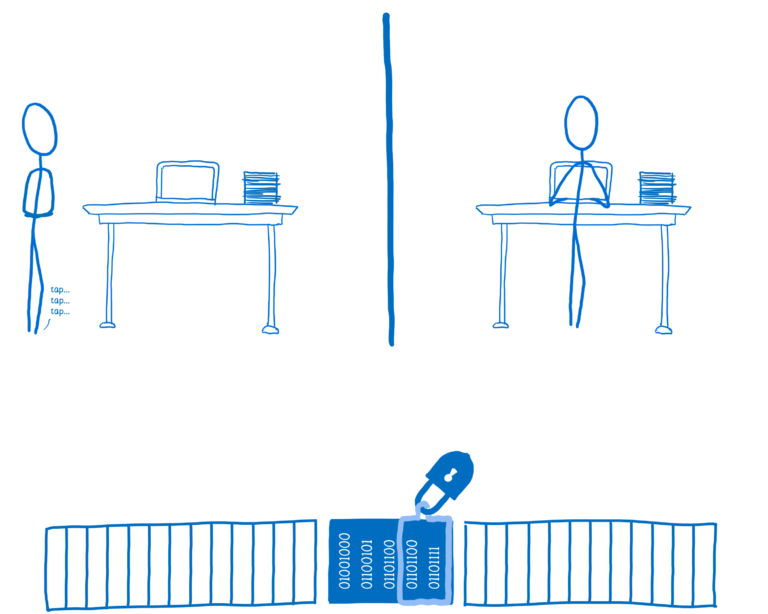
一旦线程2完成,它将调用解锁。锁将通知一个或多个等待线程它现在可用。
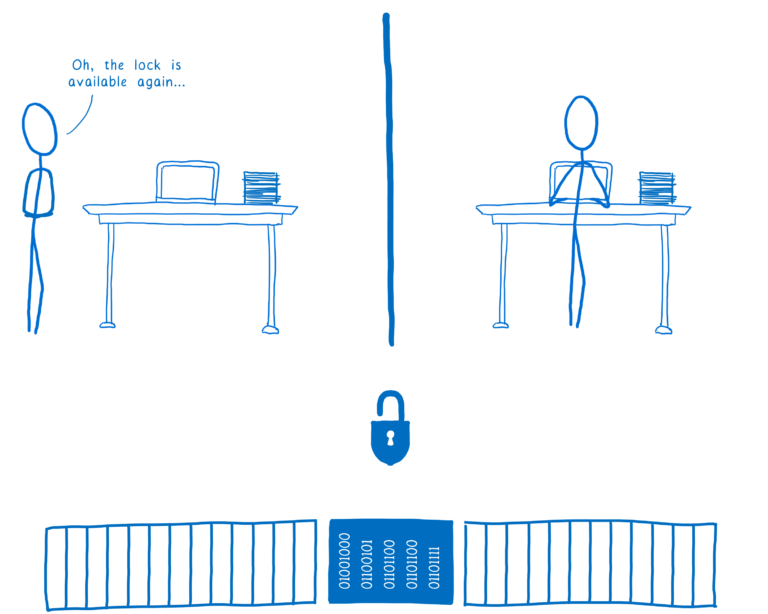
然后该线程可以挖出锁并锁定数据供自己使用。
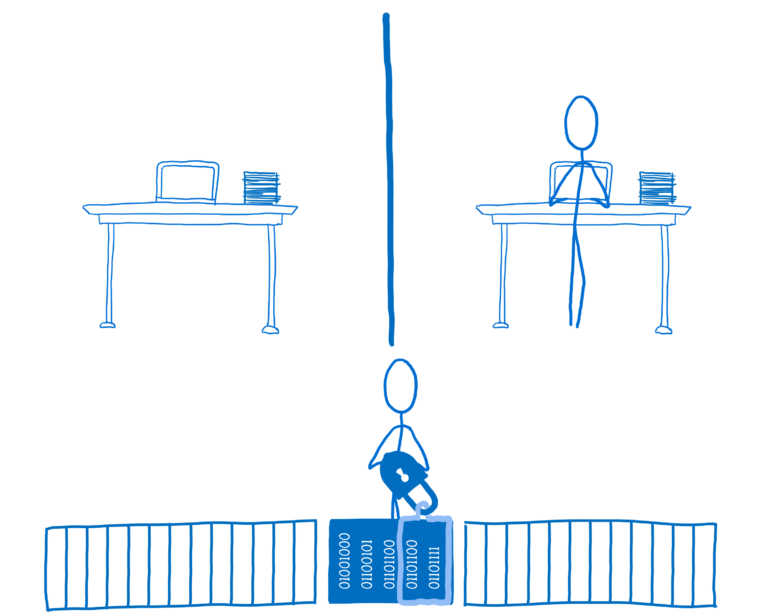
锁库将在Atomics对象上使用许多不同的方法,但对于此用例最重要的方法是:
- Atomics.wait
- Atomics.wake
指令重新排序引起的竞争条件
Atomics会解决第三个同步问题。这个可能令人惊讶。
您可能没有意识到这一点,但是您编写的代码很可能没有按照您期望的顺序运行。编译器和CPU都重新排序代码以使其运行得更快。
例如,假设您已经编写了一些代码来计算总计。您想在计算完成时设置标志。

为了编译它,我们需要决定每个变量使用哪个寄存器。然后我们可以将源代码翻译成机器的指令。

到目前为止,一切都如预期。
如果您不了解计算机在芯片级别的工作方式(以及它们用于执行代码工作的管道如何),那么我们的代码中的第2行需要等待一段时间才能执行,这一点并不明显。
大多数计算机将执行指令的过程分解为多个步骤。这可以确保CPU的所有不同部分始终处于忙碌状态,因此可以充分利用CPU。
以下是指令执行步骤的一个示例:
- 从内存中获取下一条指令
- 弄清楚指令告诉我们做什么(也就是解码指令),并从寄存器中获取值
- 执行指令
- 将结果写回寄存器
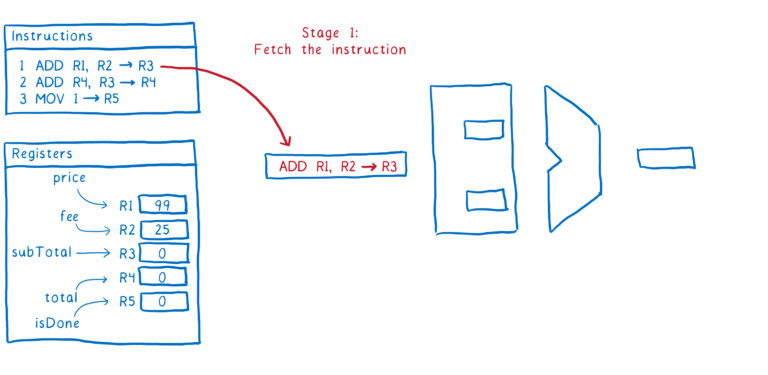
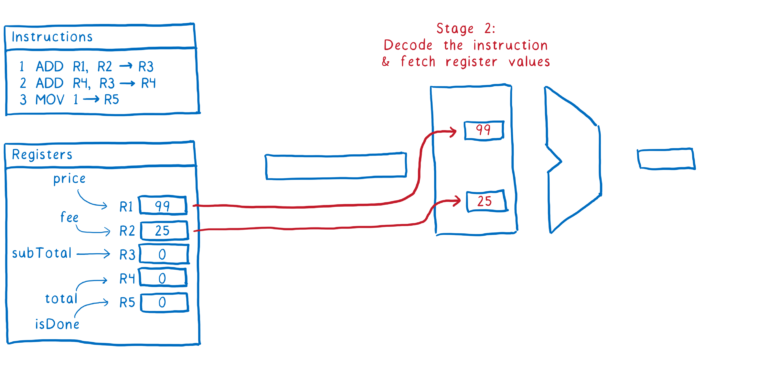
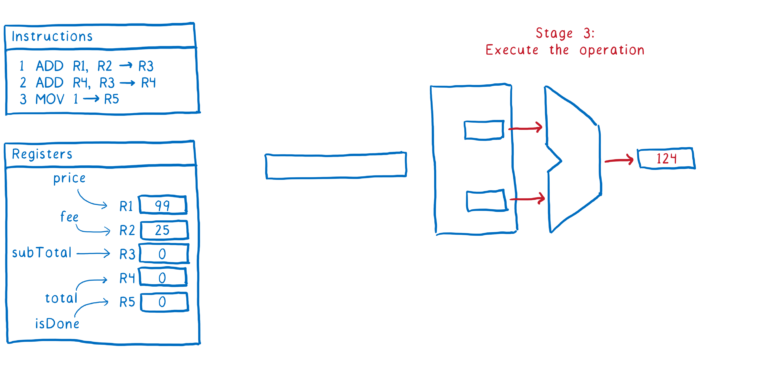
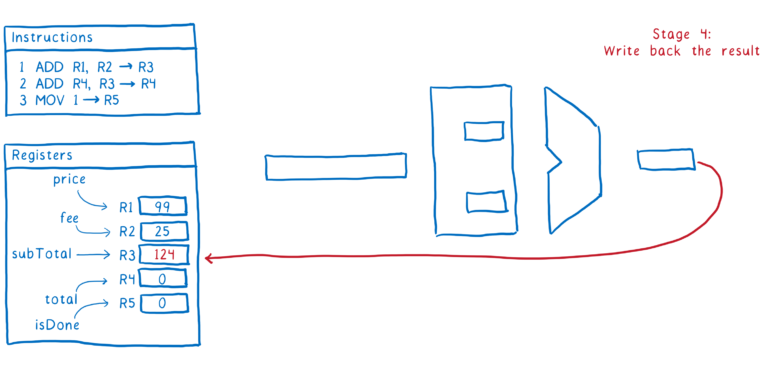
这就是一条指令通过管道的方式。理想情况下,我们希望在它之后直接跟随第二条指令。一旦进入第2阶段,我们想要获取下一条指令。
问题是指令#1和指令#2之间存在依赖关系。
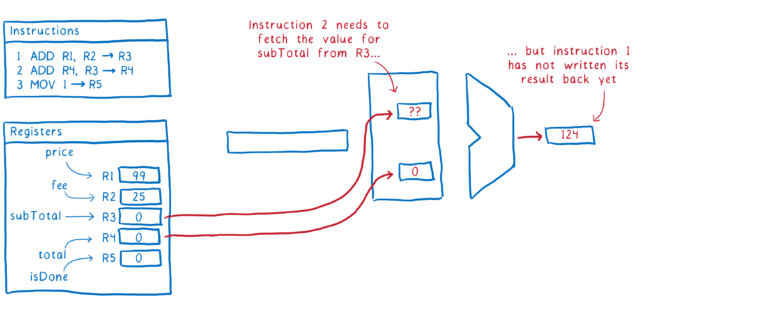
我们可以暂停CPU直到指令#1 subTotal在寄存器中更新。但这会减慢事情的速度。
为了提高效率,许多编译器和CPU将做的是重新排序代码。他们将寻找不使用其他指令subTotal或total与这两条线之间搬完英寸

这样可以保持稳定的指令流在管道中移动。
因为第3行不依赖于第1行或第2行中的任何值,所以编译器或CPU认为像这样重新排序是安全的。当你在一个线程中运行时,无论如何,在整个函数完成之前,其他任何代码都不会看到这些值。
但是当你在另一个处理器上同时运行另一个线程时,情况并非如此。另一个线程不必等到函数完成才能看到这些更改。几乎只要它们被写回内存就可以看到它们。所以它可以告诉它isDone在总计之前设定。
如果你使用isDone的total是已经计算好并且准备在另一个线程中使用的标志,那么这种重新排序会产生竞争条件。
Atomics试图解决其中的一些错误。当您使用Atomic写入时,就像在代码的两个部分之间放置一个栅栏。
原子操作不会相对于彼此重新排序,并且其他操作不会在它们周围移动。特别是,通常用于强制排序的两个操作是:
- Atomics.load
- Atomics.store
Atomics.store函数源代码中的所有变量更新都保证在将Atomics.store其值写回内存之前完成。即使非原子指令相对于彼此重新排序,它们也不会移动到Atomics.store源代码中的下面的调用之下。
并且Atomics.load在函数之后的所有变量加载都保证在Atomics.load获取其值之后完成。同样,即使非原子指令被重新排序,它们也不会被移动Atomics.load到源代码中位于它们之上的指令之上。
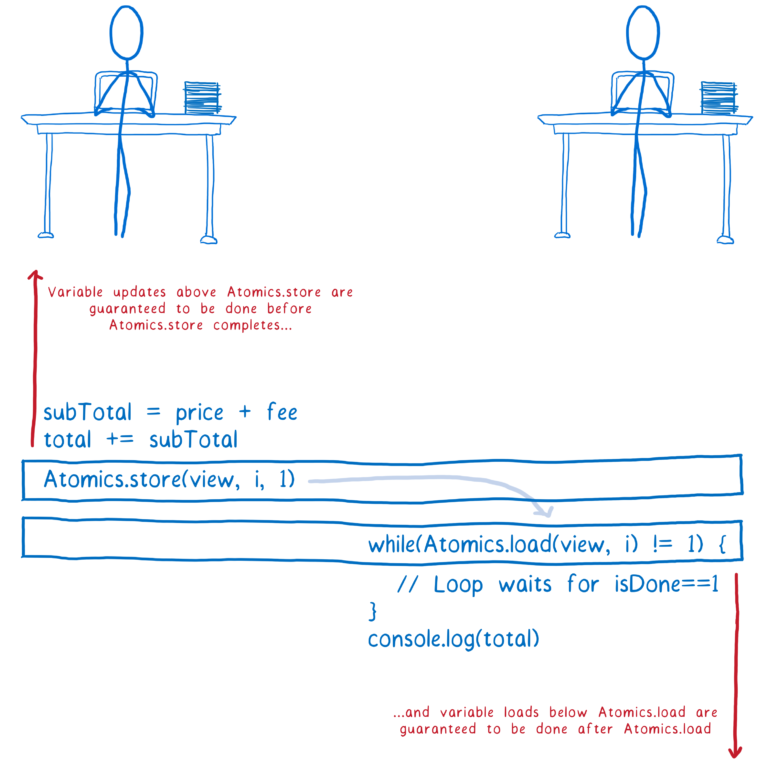
注意:我在这里展示的while循环称为自旋锁,效率非常低。如果它在主线程上,它可以使您的应用程序停止。你几乎肯定不想在实际代码中使用它。
再一次,这些方法并不真正意味着直接在应用程序代码中使用。相反,库会使用它们来创建锁。
结论
编程共享内存的多个线程很难。有许多不同种类的竞争条件等着你绊倒你。

这就是您不希望直接在应用程序代码中使用SharedArrayBuffers和Atomics的原因。相反,您应该依赖于具有多线程经验并且花时间研究内存模型的开发人员经过验证的库。
SharedArrayBuffer和Atomics仍处于早期阶段。那些图书馆尚未创建。但是这些新的API提供了构建的基础。