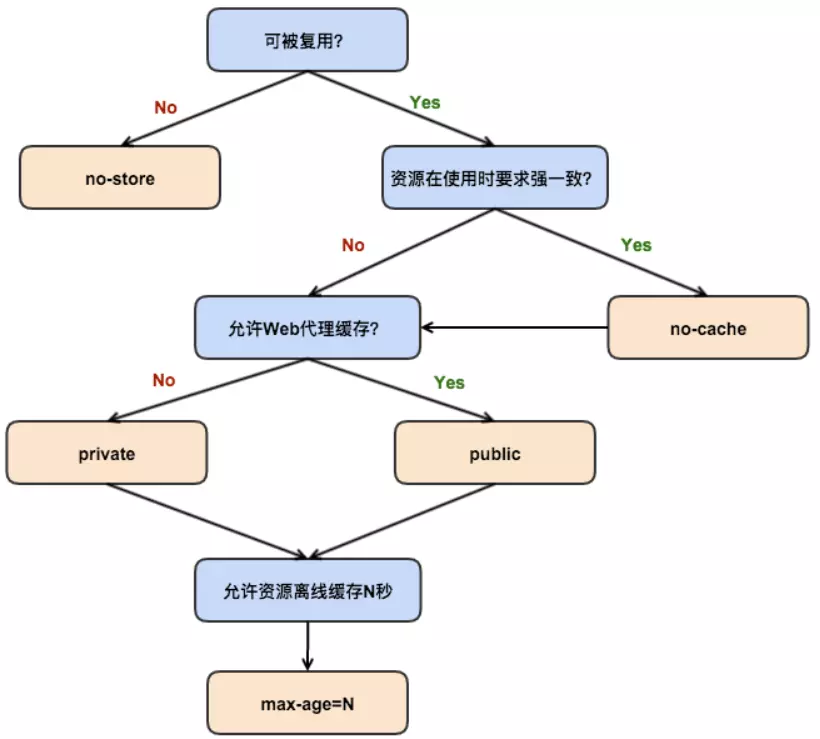
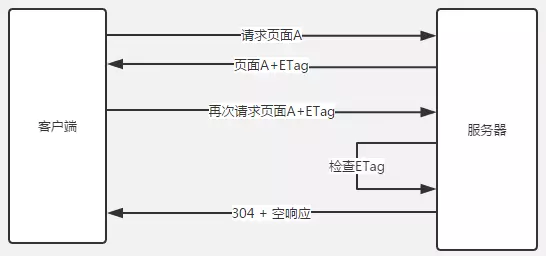
相信你已经找出了乱码的原因,由于 get 方法传的的数据,浏览器的转码规则和服务器的解码规则不一致出现了乱码,我们一般是怎么解决的呢?get 方式发送的数据如果有中文和特殊字符前端会先使用 encodeURI() 方法转码,这样 url 里面的就都是 ASCII 编码集的字符,省去了浏览器的转码,且 encodeURI() 的转码规则可控,受网页 meta 头的 charset 属性影响,
标签的 charset 属性为 utf-8 时:
1 2 3 4 5
var data = '百度&%$#@baidu'; console.log(encodeURI(data)); // %E7%99%BE%E5%BA%A6&%25$#@baidu console.log(encodeURIComponent(data)); // %E7%99%BE%E5%BA%A6%26%25%24%23%40baidu
标签的 charset 属性为 GBK 时:
1 2 3 4 5
var data = '百度&%$#@baidu'; console.log(encodeURI(data)); // %E9%90%A7%E6%83%A7%E5%AE%B3&%25$#@baidu console.log(encodeURIComponent(data)); // %E9%90%A7%E6%83%A7%E5%AE%B3%26%25%24%23%40baidu
asynchronous javascript and xml: 异步的javascript和xml。 ajax是一种用来改善用户体验的技术,其本质是利用浏览器内置的一种特殊的对象(XMLHttpRequest)异步(即发送请求时,浏览器不会销毁当前页面,用户可以继续在当前页面做其它的操作)的向服务器发送请求,并且利用服务器返回的数据(不再是一个完整的页面,只是部分的数据,一般使用文本或者xml返回)来部分更新当前页面。使用ajax技术之后,页面无刷新,并且不打断用户的操作。
使用
如何获得ajax对象?
XMLHttpRequest并没有标准化,要区分浏览器:
1 2 3 4 5 6 7 8
function getXhr(){ var xhr; if(window.XMLHttpRequest){ xhr = new XMLHttpRequest(); // 非ie浏览器 }else{ xhr = new ActiveXObject('Microsoft.XMLHttp'); // ie浏览器 } }
这是 Nginx 服务器作为 WEB 服务器的主要功能之一,客户端向服务器发送请求时,会首先经过 Nginx 服务器,由服务器将请求分发到相应的 WEB 服务器。正向代理是代理客户端,而反向代理则是代理服务器,Nginx 在提供反向代理服务方面,通过使用正则表达式进行相关配置,采取不同的转发策略,配置相当灵活,而且在配置后端转发请求时,完全不用关心网络环境如何,可以指定任意的IP地址和端口号,或其他类型的连接、请求等。
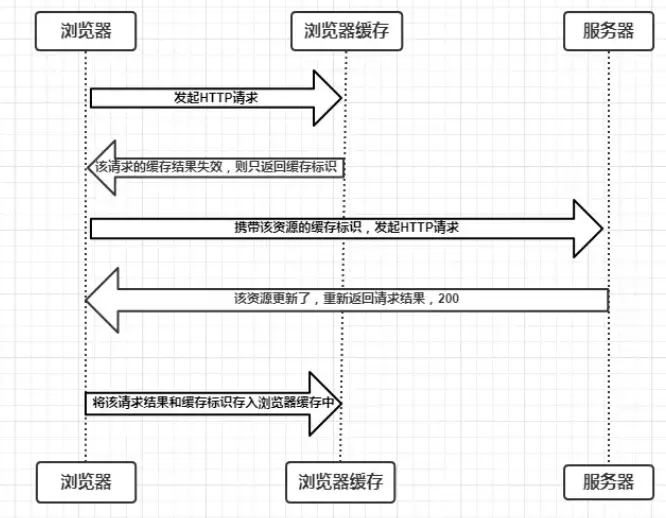
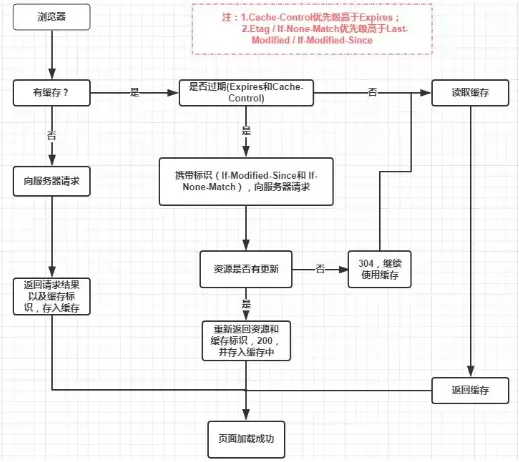
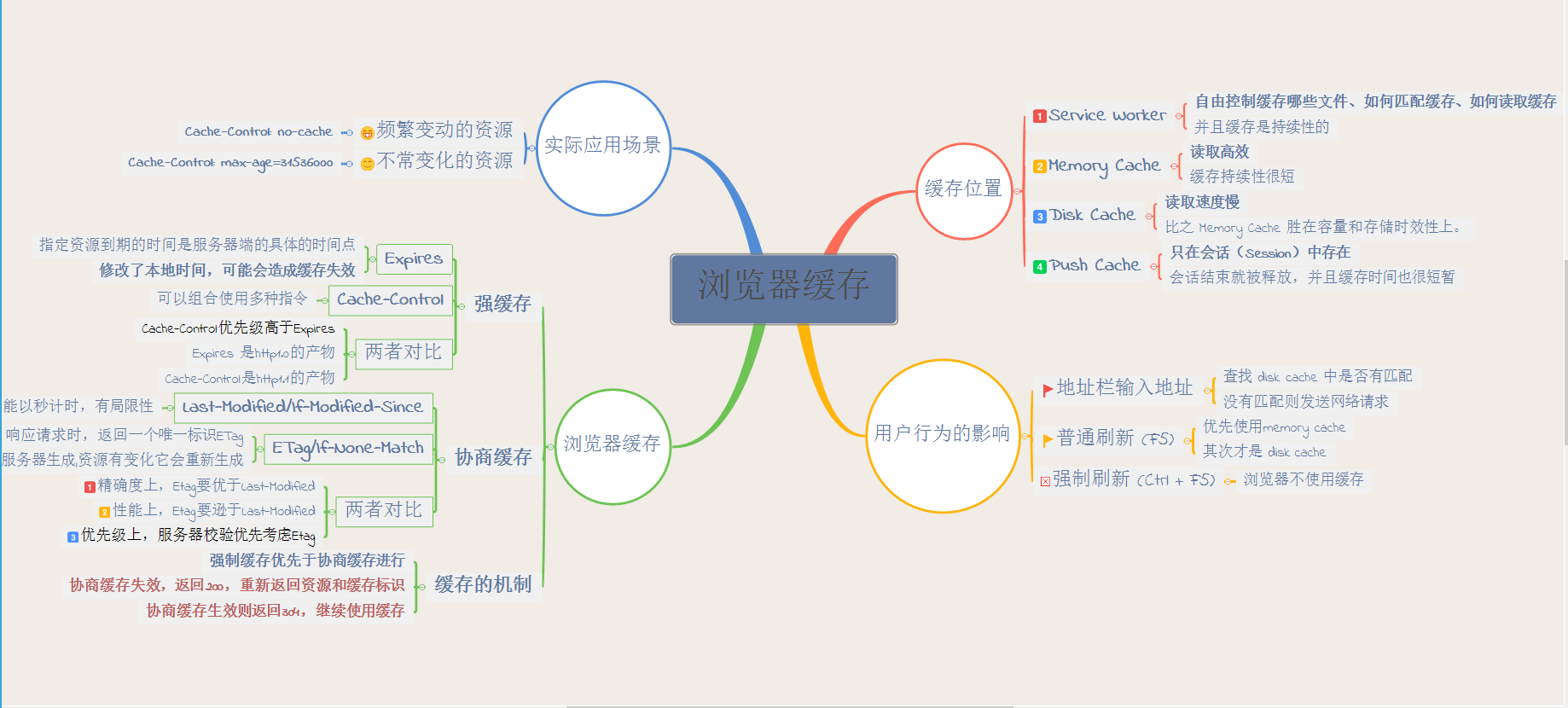
Service Worker 是运行在浏览器背后的独立线程,一般可以用来实现缓存功能。使用 Service Worker的话,传输协议必须为 HTTPS。因为 Service Worker 中涉及到请求拦截,所以必须使用 HTTPS 协议来保障安全。Service Worker 的缓存与浏览器其他内建的缓存机制不同,它可以让我们自由控制缓存哪些文件、如何匹配缓存、如何读取缓存,并且缓存是持续性的。 Service Worker 实现缓存功能一般分为三个步骤:首先需要先注册 Service Worker,然后监听到 install 事件以后就可以缓存需要的文件,那么在下次用户访问的时候就可以通过拦截请求的方式查询是否存在缓存,存在缓存的话就可以直接读取缓存文件,否则就去请求数据。 当 Service Worker 没有命中缓存的时候,我们需要去调用 fetch 函数获取数据。也就是说,如果我们没有在 Service Worker 命中缓存的话,会根据缓存查找优先级去查找数据。但是不管我们是从 Memory Cache 中还是从网络请求中获取的数据,浏览器都会显示我们是从 Service Worker 中获取的内容。
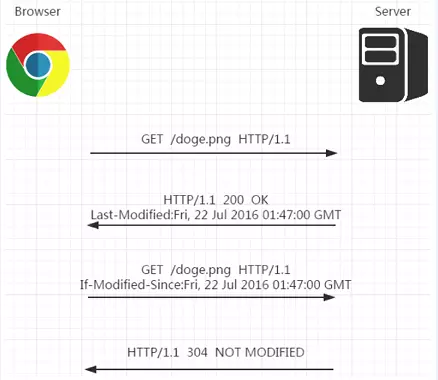
Disk Cache 也就是存储在硬盘中的缓存,读取速度慢点,但是什么都能存储到磁盘中,比之 Memory Cache 胜在容量和存储时效性上。 在所有浏览器缓存中,Disk Cache 覆盖面基本是最大的。它会根据 HTTP Herder 中的字段判断哪些资源需要缓存,哪些资源可以不请求直接使用,哪些资源已经过期需要重新请求。并且即使在跨站点的情况下,相同地址的资源一旦被硬盘缓存下来,就不会再次去请求数据。绝大部分的缓存都来自 Disk Cache,关于 HTTP 的协议头中的缓存字段,我们会在下文进行详细介绍。 浏览器会把哪些文件丢进内存中?哪些丢进硬盘中? 关于这点,网上说法不一,不过以下观点比较靠得住:
对于大文件来说,大概率是不存储在内存中的,反之优先 当前系统内存使用率高的话,文件优先存储进硬盘
4.Push Cache
Push Cache(推送缓存)是 HTTP/2 中的内容,当以上三种缓存都没有命中时,它才会被使用。它只在会话(Session)中存在,一旦会话结束就被释放,并且缓存时间也很短暂,在Chrome浏览器中只有5分钟左右,同时它也并非严格执行HTTP头中的缓存指令。 Push Cache 在国内能够查到的资料很少,也是因为 HTTP/2 在国内不够普及。这里推荐阅读Jake Archibald的 HTTP/2 push is tougher than I thought 这篇文章,文章中的几个结论:
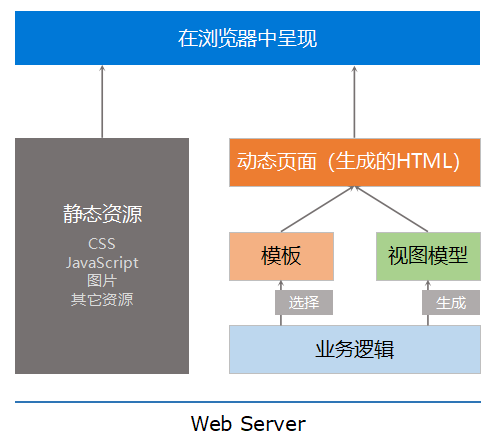
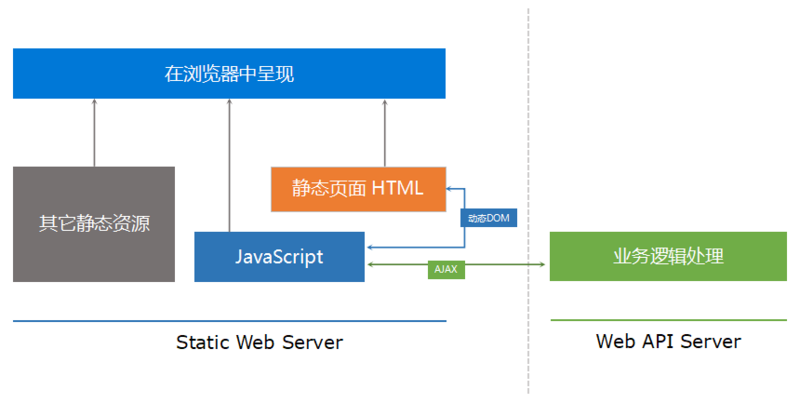
老牌的一些大公司可能有些产品是用不同的计算机语言开发的,但是项目之前可能会存在大量重复性的工作。在这种情况下,如果前端实现与后端技术无关,那页面呈现的部分就可以共用,不同的后端技术只需要实现后端业务逻辑就好。分离老项目首先解决的问题是把数据和页面剥离开来。应对这种需求的技术是现成的,前端采用静态网页相关的技术,HTML + CSS + JavaScript,通过 AJAX 技术调用后端提供的业务接口。前后端协商好接口方式通过 HTTP 提供,统一使用 POST 谓词。接口数据结构使用 XML 实现,前端 jQuery 解析 XML 很方便,后端对 XML 的处理工具就更多了……后来由于后端 JSON库(比如 Newtonsoft JSON.NET、jackson、Gson 等)崛起,前端处理 JSON 也更容易(JSON.parse() 和 JSON.stringify()),就将数据结构换成了 JSON 实现。
这种架构从本质上来说就是 SOA(面向服务的架构)。当后端不提供页面,只是纯粹的通过 Web API 来提供数据和业务交互能力之后,Web 前端就成了纯粹的客户端角色,与 WinForm、移动终端应用属于同样的角色,可以把它们合在一起,统称为前端。以前的一体化架构需要定制页面来实现 Web 应用,同时又定义一套 WebService/WSDL 来对 WinForm 和移动终端提供服务。转换为新的架构之后,可以统一使用 Web API 形式为所有类型的前端提供服务。至于某些类型的前端对这个 Web API 进行的 RPC 封装,那又是另外一回事了。
通过这样的架构改造,前后端实际就已经分离开了。抛开其它类型的前端不提,这里只讨论 Web 前端和后端。由于分离,Web 前端在开发的时候压根不需要了解后端是用的什么技术,只需要后端提供了什么样的接口可以用来做什么事情就好,什么 C#/ASP.NET、Java/JEE、数据库……这些技术可以统统不去了解。而后端的 .NET 团队和 Java 团队也脱离了逻辑无关的美学思维,不需要面对美工精细的界面设计约束,也不需要在思考逻辑实现的同时还要去考虑页面上怎么布局的问题,只需要处理自己擅长的逻辑和数据就好。
前后端分离指的是
前后职责分离 前端倾向于呈现,着重处理用户体验相关的问题;后端则倾处于业务逻辑、数据处理和持久化等。在设计清晰的情况下,后端只需要以数据为中心对业务处理算法负责,并按约定为前端提供 API 接口;而前端使用这些接口对用户体验负责。
前后技术分离 前端可以不用了解后端技术,也不关心后端具体用什么技术来实现,只需要会 HTML/CSS/JavaScript 就能入手;而后端只需要关心后端开发技术,除了省去学习前端技术的麻烦,连 Web 框架的学习研究都只需要关注 Web API 就好,而不用去关注基于页面视图的 MVC 技术(并不是说不需要 MVC,Web API 的接口部分的数据结构呈现也是 View),不用考虑特别复杂的数据组织和呈现。
前后分离,可以分别归约两端的设计 后端只提供 API 服务,不考虑页面呈现的问题。实现 SOA 架构的 API 可以服务于各种前端,而不仅仅是 Web 前端,可以做到一套服务,各端使用;同时对于前端来说,不依赖后端技术的前端部分可以独立部署,也可以应于 Hybrid 架构,嵌入各种“壳”(比如 Electron、Codorva 等),迅速实现多终端。
前后分离之后,前端的测试将以用户体验测试和集成测试为主,而后端则主要是进行单元测试和 Web API 接口测试。与一体化的 Web 应用相比,多了一层接口测试,这一层测试可以完全自动化,一旦完成测试开发,就能在很大程度上控制住业务处理和数据错误。这样一来,集成测试的工作量会相对单一也容易得多。
前端测试的工作相对来说减轻不了多少,前后分离之后的前端部分承担了原来的集成测试工作。但是在假设 Web API 正确的情况下进行集成测试,工作量是可以减轻不少的,用例可以只关注前端体验性的问题,比如呈现是否正确,跳转是否正确,用户的操作步骤是否符合要求以及提示信息是否准确等等。
对于用户输入有效性验证这部分工作在项目时间紧迫的情况下甚至都可以完全抛给 Web API 去处理。不管是否前后端分离,Web 开发中都有一个共识:永远不要相信前端!既然后端必须保证数据的安全性和有效性,那么前端省略这一步骤并不会对后端造成什么实质性的威胁,最多只是用户体验差一点。但是,如果前后端都要做数据有效性验证,那一定要严格按照文档来进行,不然很容易出现前后端数据验证不一致的情况(这不是前后分离的问题,一体化架构同样存在这个问题)。
总结
总的来说,前后分离所带来的好处还是很明显的。但是具体实施的时候需要一个全新的思考方式,而不是基于原有一体化 Web 开发方式来进行思考。前后分离的开放方式将开发人员从复杂的技术组合中解放出来,大家都可以更专注于自己擅长的领域来进行开发,但同时也对前后端团队的沟通交流提出了更高的要求,前后端团队必须要一同设计出相对稳定的 Web API 接口(这部分工作其实不管是否前后端分离都是少不了的,只是前后分离的架构对此要求更高,更明确地要求接口不只存在于人的记忆中,更要文档化、持久化)。